
We recently introduced changes in the client drivers that affects how incoming requests are distributed across an Apache Cassandra cluster. The new default load balancing algorithm that is being rolled out in the drivers helps reduce long tail latency and provides better overall response times.
How data partitioning and replication works in Cassandra
Cassandra places the data on a node according to the value of the partition key. For each partition key, multiple replicas are used to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed. The total number of replicas across the cluster is referred to as the replication factor. For example, a replication factor of 3 means that there are three replicas of each row in a given data center or cluster.
For a given query request, the driver selects a replica that acts as coordinator for the query and is responsible for meeting the consistency level guarantees.
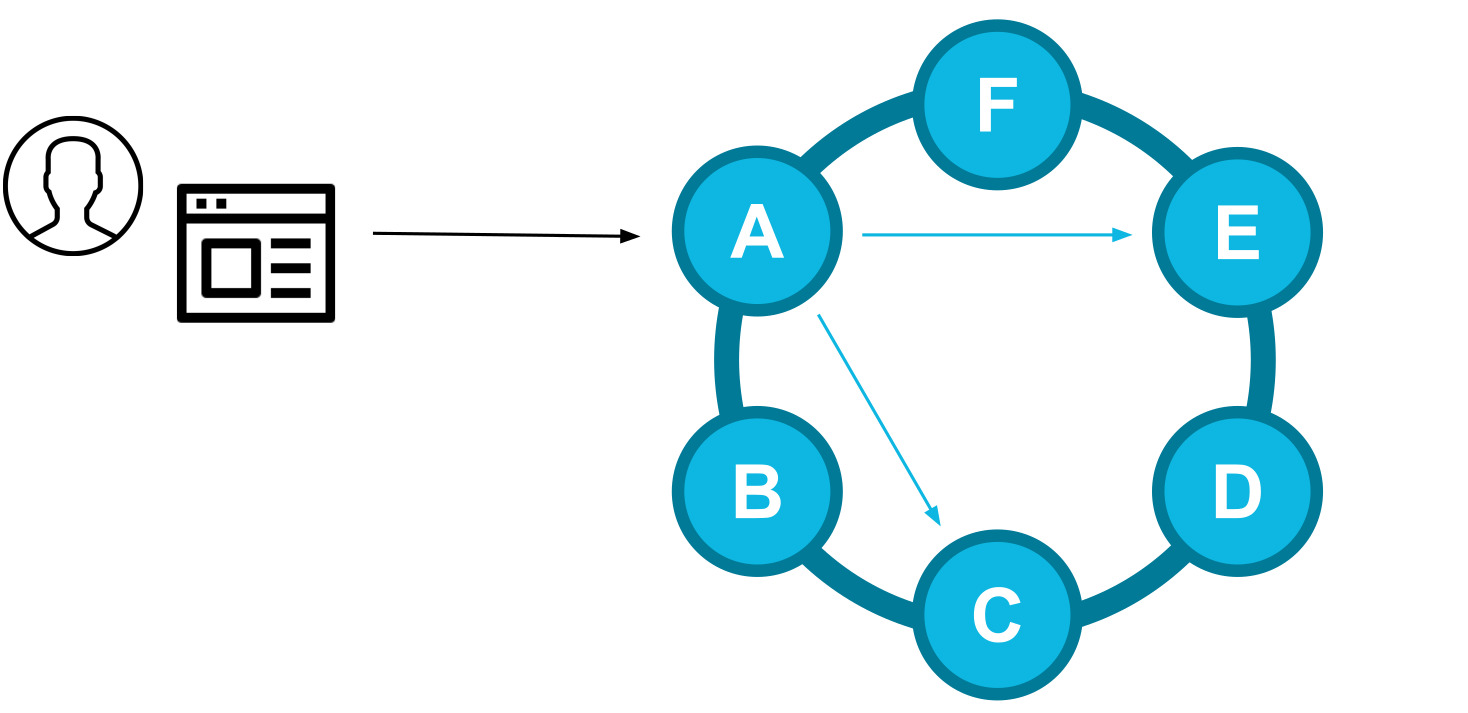
How client routing works
The DataStax Drivers control the distribution of incoming queries across the cluster. Using cluster metadata, the driver knows which nodes are replicas for a given key, sending the query request directly to a replica to avoid extra network hops.
When the replication factor is greater than 1, the driver balances the requests across the different replicas. Historically, the drivers used to select the coordinator of the query from the replica set in a random manner.
Random selection
Given that microservice applications usually consist of multiple service instances, we have to consider the client driver as a distributed load balancer (n clients routing traffic to m nodes). Random selection makes a good distributed load balancer algorithm because it's stateless, requires no communication between client instances and generates a uniform load.
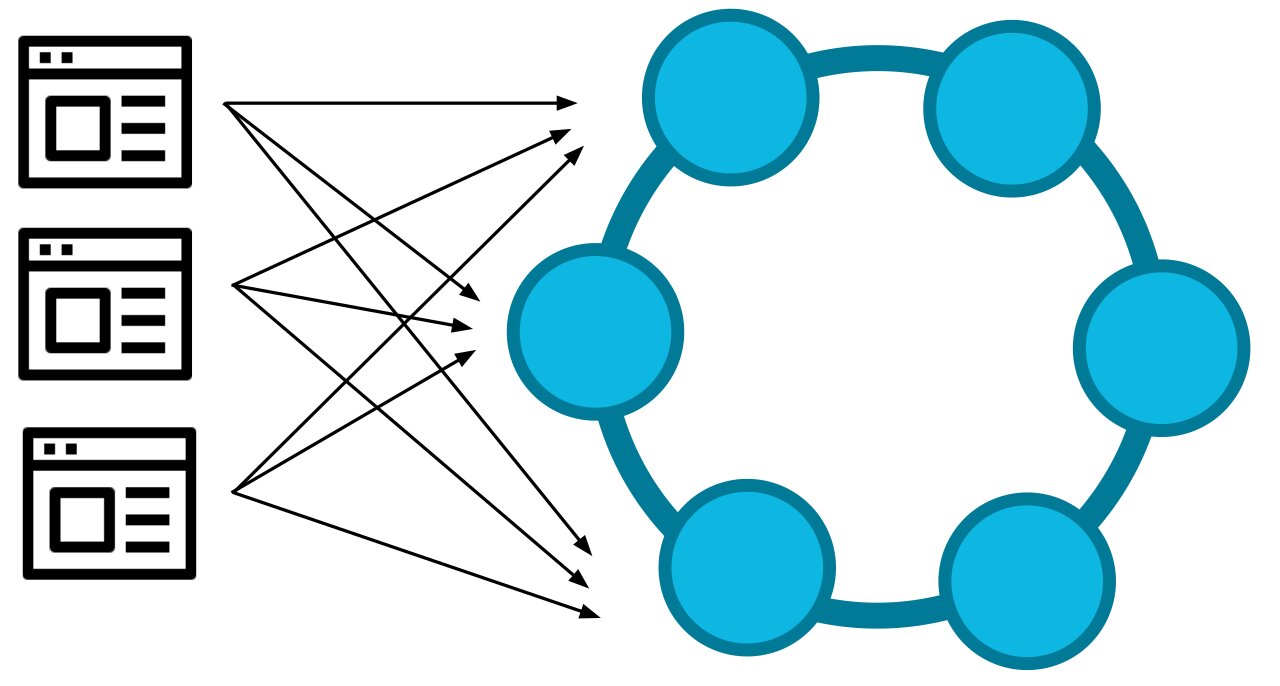
With random selection, the request load is distributed uniformly but not in a fair manner: it doesn't account for size/complexity of the requests and other tasks that might be occurring in the background of the server node.
Power of two random choices
Deterministically selecting a single candidate based on a signal can be dangerous in a distributed system: multiple clients with the same logic may identify the same server node as the best candidate and redirect all traffic to it, causing load spikes and risking a cascading failure. For this reason, we still need an algorithm with some degree of randomness.
We first encountered the Power of Two Random Choices algorithm via this talk by Tyler McMullen. Since then, it has been implemented by load balancing software like Netflix's Zuul, Nginx and Haproxy and in numerous service mesh deployments, like at Twitter. The logic is simple: instead of trying to select the absolute best candidate using a signal, with “power of two choices” you pick two candidates at random and choose the better option of the two, avoiding the worse choice.
There are several approaches we can use to identify a node as a best candidate. In the past, we exposed a way to use latency information (LatencyAwarePolicy) as a signal. Since we are routing database requests without considering the complexity of the queries, using aggregated latency information of a node is not a good indicator of current health or state of the server instance. For example, a query might take longer because it involves consolidating lots of data but the server could still have plenty of resources available for handling other queries. Additionally, the response time of a request is determined after the response is received, providing an out-of-date view of the server state.
We decided to choose the best candidates using the number of in-flight requests to each node from the client driver instance. In a nutshell, we select two replicas at random and we pick the replica with fewer in-flight requests as coordinator.
Stale queue detection
Thanks to our knowledge of how the nodes behave, we found more room for improvement. When a node is undergoing compaction or GC, it might take longer to process items from the request queue. Even if the request queue for a node is stale, under a scenario of increased load the client driver might continue to route traffic to it if we base the algorithm solely on the shortest queue.
As an example, consider the following scenario.
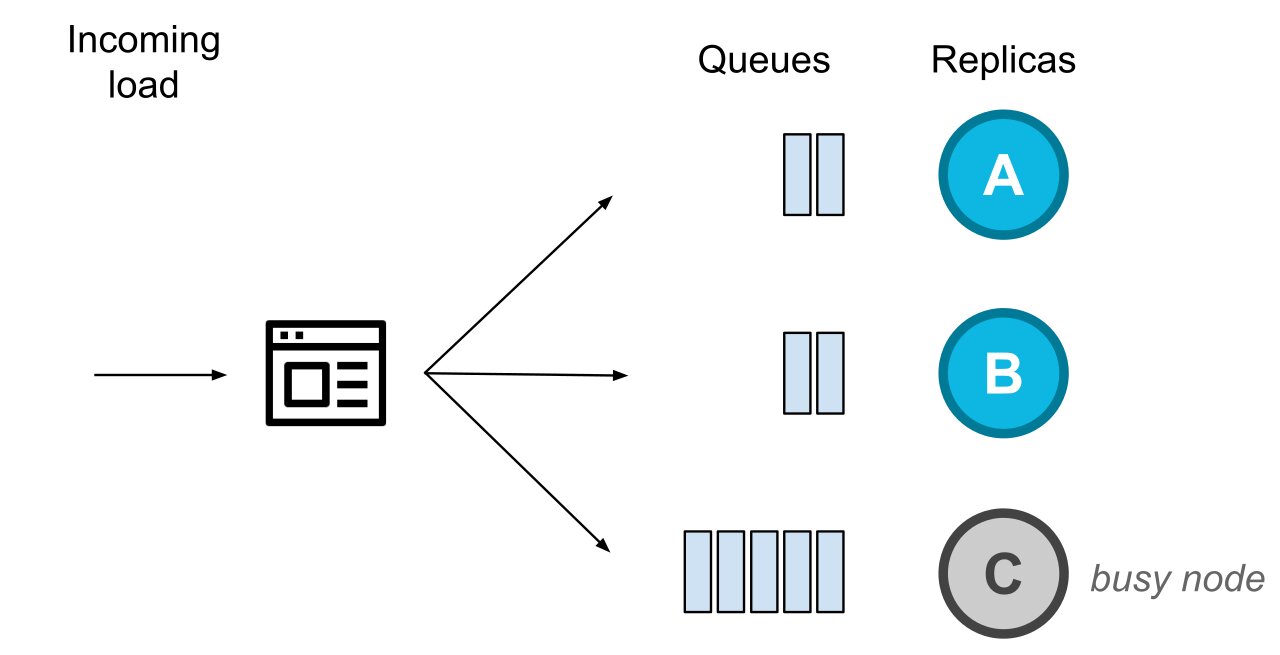
There's a steady flow of requests and a client driver instance within an application is balancing requests between the replicas. At some point in time, the node C becomes busy (doesn't process requests for some time). The other healthy replicas will continue processing requests like the diagram shows.
At the same time the incoming load to the system increases, to which point that the healthy replicas have a larger number of in-flight requests.
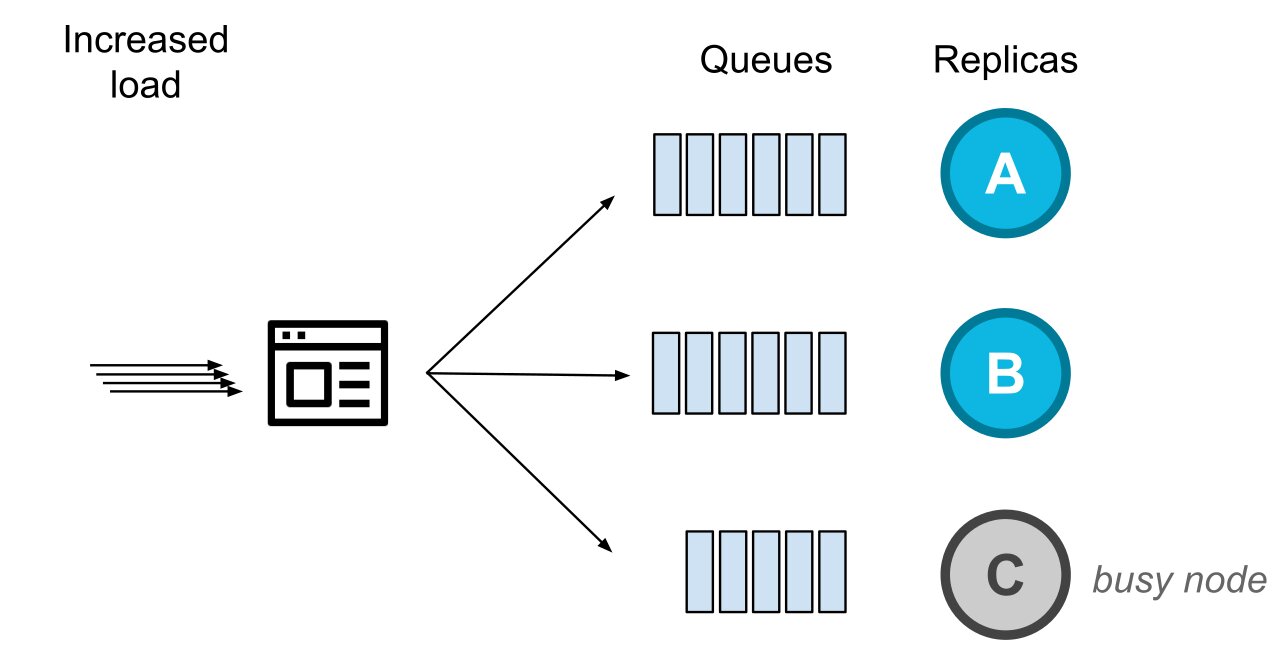
In that case, we would still be routing requests to a node we know is not processing them at a healthy pace.
To overcome the scenario explained above, we introduced a second indicator: whether a node has requests in-flight (10+) and hasn't sent back any response in the last few hundred milliseconds. This second indicator is not factored in as a signal of the power of two choices but as initial probing of the health of the replicas.
When there is a majority of healthy replicas, unhealthy ones are excluded as initial coordinators (will still be considered for retries and speculative executions). Why probing the health of replicas as a first step? Because if there are a large number of nodes being considered unhealthy, it could mean that this indicator doesn't apply the workload or/ type of queries or expected latencies. That way, we make sure we don't make things worse by making bad decisions based on a signal that in a particular case doesn't apply.
Summary
We tested the new algorithm against a series of scenarios with multiple clients at the same time, simulating nodes under stress using CPU burns (stress-ng) and artificial network latency (tc) and the result is that the new algorithm outperformed all other approaches.
As a sample, the following diagram shows latency by percentile distribution, comparing the new algorithm to random selection with some of the nodes experiencing CPU burns.
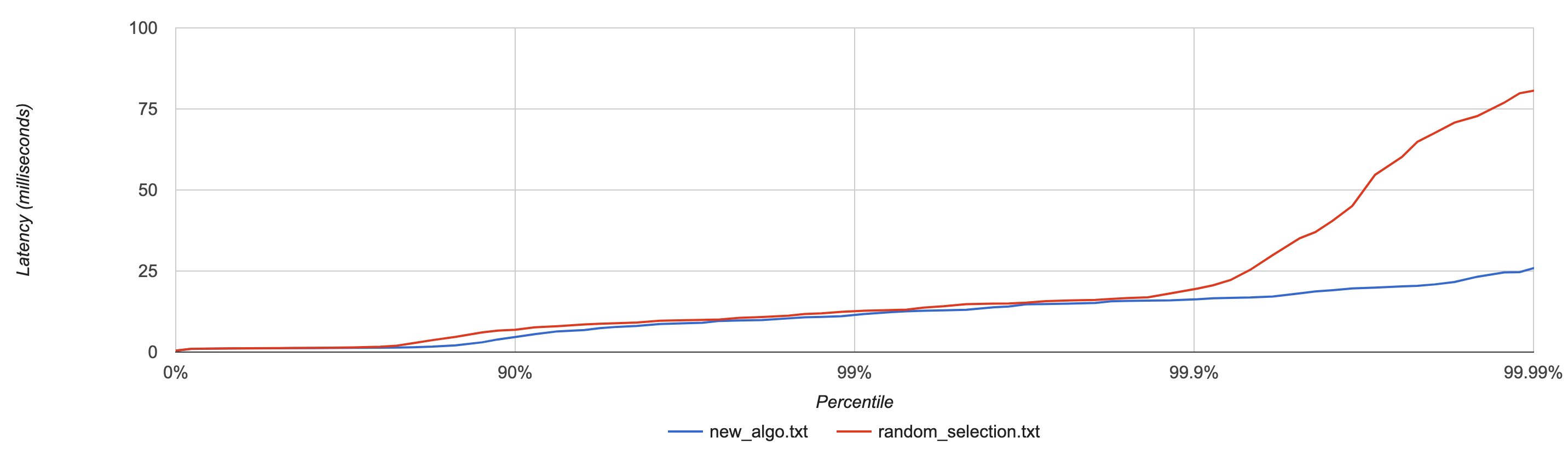
The new load balancing algorithm, based on power of two choices with additional logic for busy node avoidance, is becoming the new default on the DataStax drivers. With a simple logic, it avoids the undesired herd behavior by bypassing the worst candidate and still distributing traffic with a degree of randomness, resulting in significant lower tail latencies.
We are still rolling it out across all client drivers, with Java and Node.js drivers already using this algorithm as default since version 4.4 and the rest of the drivers following shortly after. If you have questions or doubts, feel free to reach us on the mailing lists for C++, C#, Java, Node.js and Python drivers.





